[파이썬 알고리즘] Ch 6-1. 기수 정렬(Radix Sort)
참고 도서: 최영규, ⌜파이썬 알고리즘⌟ 생능츨판, 2021
지금까지 다루었던 정렬 방법들은 모두 배열의 요소들을 서로 비교하여 정렬하였다. 그런데 이러한 비교 연산을 사용하지 않고도 데이터를 정렬할 수 있는 독특한 정렬 기법들이 있다.
<비교 기반의 정렬(Comparsion based sorting)>
- 요소들 끼리 비교하는 것에 기반한 정렬 알고리즘이다.
- 입력 값의 종류에 대한 제한이 없다.
- 최소 비교 횟수의 이론적 하한(Lower bound)이 존재하는데 이는 어떤 비교 정렬 알고리즘이라도 $O(n log_{2}n)$시간이 소요된다는 것을 의미한다.
- 버블 정렬, 선택 정렬, 삽입 정렬, 힙 정렬, 병합 정렬, 퀵 정렬이 있다.
<배분 기반의 정렬(Distributiom-based sorting)>
- 값의 범위나 특성을 기반으로 메모리에 나누어 분류하는 방식의 정렬 알고리즘이다.
- 입력의 종류에 대한 제한이 있다.
- 추가적인 메모리가 필요하다.
- 비교 기반 정렬의 이론적 하한(Lower bound)보다 더 빠른 정렬이 가능하다.
- 기수 정렬, 카운팅 정렬이 있다.
1. 용어 정리
기수(radix): 숫자의 자릿수
$e.g.$ 숫자 35는 3과 5 두 개의 자릿수를 가지고 있고, 이것이 기수가 된다.
버킷(bucket): 정렬 시 사용되는 추가 메모리로 기수 정렬에서 버킷은 큐(queue)를 사용한다.
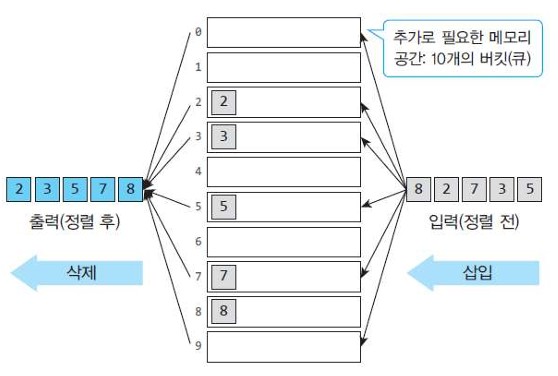
2. 한 자릿수의 정렬
$e.g.$
한 자리로만 이루어진 숫자 리스트 [8, 2, 7, 3, 5]를 정렬하려고 한다.
어떻게 서로 비교를 하지 않고 정렬할 수 있을까?
$sol.$
아래 과정에서 비교 연산은 전혀 사용되지 않았다.
단, 정렬을 위한 추가 메모리(10개의 버킷)이 사용되었음을 확인할 수 있다.
1
2
3
항목들을 저장할 버킷(bucket)을 준비한다.
입력 할목들을 순서대로 키값(value)에 따라 해당 버킷에 넣는다.
위쪽 버킷부터 순차적으로 버킷 안에 들어 있는 숫자를 출력한다.
3. 여러 자리 숫자의 정렬
$e.g.$
여러 자리로 이루어진 숫자 리스트 [28, 93, 39, 81, 62, 72, 38, 26]를 정렬하려고 한다.
어떻게 서로 비교하지 않고 정렬할 수 있을까?
$sol \ 1.$
위 방법과 동일하게 0에서 999까지 번호가 매겨진 1000개의 버킷을 사용한다.
→ 자릿수가 커질 수록 사용해야 할 추가 메모리도 늘어나기 때문에 그다지 좋은 방법은 아니다..
$sol \ 2.$
위와 같이 10개의 버킷만 사용하되, 먼저 낮은 자릿수로 정렬하고, 그 다음 높은 자릿수에 대해 정렬해 나가는 방법을 사용한다.
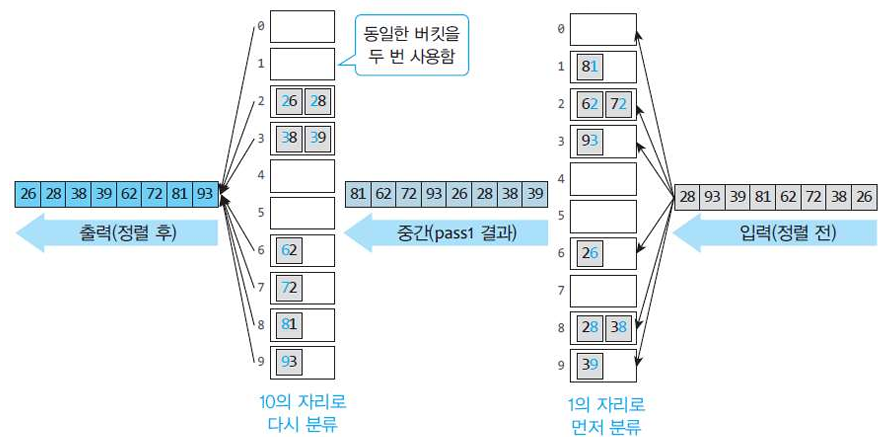
만약 숫자를 10진법으로 나타낸다면?
→ 버킷 10개만 있으면 정렬이 가능하다!
만약 숫자를 2진법으로 나타낸다면?
→ 버킷 2개만 있으면 정렬이 가능하다!
4. 기수 정렬 알고리즘
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
from queue import Queue
import random
# 기수 정렬 함수
def radix_sort(A):
queues = []
for i in range(BUCKETS): # BUCKETS 개의 큐 사용
queues.append(Queue())
n = len(A)
factor = 1 # 1의 자리부터 정렬 시작
for d in range(DIGITS): # 모든 자리에 대해
for i in range(n): # 자릿수에 따라 큐에 삽입
queues[(A[i]//factor) % BUCKETS].put(A[i]) # 리스트의 i번째 숫자를 현재 자릿수 값에 따라 해당 번호의 큐에 삽입
j = 0
for b in range(BUCKETS): # 버킷에서 꺼내서 원래의 리스트로 옮김
while not queues[b].empty(): # b번째 큐가 공백이 아닌 동안
A[j] = queues[b].get() # 원소를 꺼내어 리스트에 저장
j += 1
factor *= BUCKETS # 그 다음 자릿수로 이동
print("step", d+1, A) # 회차별 정렬에 대한 결과 출력(과정 출력)
# 기수 정렬 테스트
BUCKETS = 10 # 10진수
DIGITS = 4 # 최대 4자릿수
data = []
for i in range(10): # 랜덤 숫자 요소의 리스트 생성
data.append(random.randint(1, 9999))
print("non-sorted list: ", data) # 생성된 랜덤 리스트 출력
radix_sort(data)
print("Radix sorted list: ", data) # 기수 정렬 완료된 리스트 출력
1
2
3
4
5
6
7
# 출력 결과
non-sorted list: [9741, 9310, 3603, 5511, 2920, 416, 7751, 2903, 6967, 864]
step 1 [9310, 2920, 9741, 5511, 7751, 3603, 2903, 864, 416, 6967]
step 2 [3603, 2903, 9310, 5511, 416, 2920, 9741, 7751, 864, 6967]
step 3 [9310, 416, 5511, 3603, 9741, 7751, 864, 2903, 2920, 6967]
step 4 [416, 864, 2903, 2920, 3603, 5511, 6967, 7751, 9310, 9741]
Radix sorted list: [416, 864, 2903, 2920, 3603, 5511, 6967, 7751, 9310, 9741]
5. 복잡도 분석
5-1. 시간 복잡도
외부 루프(12행): $O(d)$
- 항상 DIGITS번 반복된다.
- 즉, 외부 루프의 반복 횟수는 입력 크기 $n$과 무관하고, 최대 자릿수 $d$에 의해 결정된다.
내부 루프(13행): $O(n)$
- 큐(버킷)에 숫자를 삽입하는 구문으로 정확히 원소의 개수인 $n$번 반복된다.
내부 이중루프(18-19행): $O(n)$
- 큐(버킷)에서 원소를 꺼내는 구문으로 원소의 개수인 $n$번 반복된다.
→ 따라서, 기수 정렬은 $O(dn)$의 시간 복잡도를 갖는다.
5-2. 공간 복잡도
입력 리스트 A
- 입력을 위해 주어진 공간이므로 공간 복잡도 계산에서 보통 제외한다.
큐(버킷) 리스트 queues
- 큐의 개수는 상수개 이므로 $O(1)$
큐 안에 저장되는 원소들
- 모든 원소 $n$개가 어떤 큐에는 반드시 들어간다.
- 즉, 큐 전체가 차지하는 공간은 최대 $n$개 이므로 $O(n)$
→ 따라서, 기수 정렬읜 $O(n)$의 공간 복잡도를 갖는다.
6. 기수 정렬의 단점
- 정렬에 사용되는 키값(value)이 자연수로 표현되는 경우에만 기수 정렬이 가능하다.
- 실수, 한글, 한자 등으로 이루어진 키값(value)에 대해서는 거의 정렬이 불가능하다.