[파이썬 알고리즘] Ch 6-3. 문자열 매칭 (1) Horspool Algorithm
참고 도서: 최영규, ⌜파이썬 알고리즘⌟ 생능츨판, 2021
문자열 매칭 문제는 길이가 $n$인 텍스트 속에서 길이가 $m$인 패턴의 위치를 찾는 문제이다.
억지 기법(brute force)을 적용하면 최악의 경우 텍스트의 $n-m+1$개 위치에서 각각 $m$번의 비교를 해야 하므로 시간 복잡도는 $O(nm)$이지만, 평균적으로는 이보다 훨씬 좋은 $O(n+m)$의 성능을 보이는 것으로 알려져 있다.
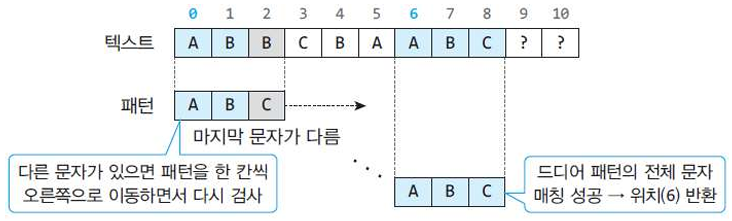
< 효율적인 문자열 매칭을 위한 기본 전략 >
- 패턴을 빠르게 검색할 수 있도록 전처리(preprocessing)을 통해 필요 정보를 미리 저장해두고,
- 패턴을 검사할 때 이를 활용한다.
1. 호스풀 알고리즘(Horspool algorithm)
호스풀 알고리즘(Horspool algorithm)은 문자열 패턴의 마지막 문자를 기준으로 비교를 수행하며, 불일치가 발생하면 해당 문자에 대해 미리 계산된 이동 거리를 이용해 패턴을 이동시키는 휴리스틱 기반의 문자열 검색 알고리즘이다.
휴리스틱(heuristic)
- 모든 경우에 대해 최적의 성능을 보장하지는 않지만, 대부분의 경우에서 꾸준히 좋은 성능을 내는 방법
호스풀 알고리즘의 기본 전략은 다음과 같다.
2. 전처리(preprocessing)
- 패턴 불일치가 발생할 경우 이동 거리를 계산하기 위한 시프트 테이블(shift table) 생성
3. 문자열 패턴 검사
- 항상 패턴의 마지막 문자부터 비교 (오른쪽 → 왼쪽)
이 방식은 불일치 발생 시 여러 위치를 한 번에 건너뛸 수 있어서 불필요한 비교를 줄이는 데 효과적이다.
< 앞에서 부터 비교 >
- 첫 글자가 우연히 일치할 수 있음
- 이후 비교 과정에서 뒤쪽 문자에서 불일치가 발생할 수 있음
- 따라서, 여러 글자를 비교한 뒤에 불일치를 판단하게 됨
< 뒤에서 부터 비교 >
- 첫 비교에 바로 일치 or 불일치를 판단할 수 있음
- 불일치 시 해당 문자를 기준으로 이동 거리 계산 가능

다음으로 문자열 패턴 검사 시 발생할 수 있는 상황에 대해 알아보자.
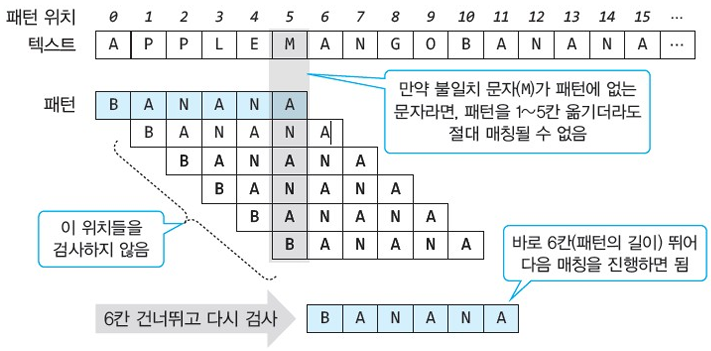
< $Case \ 1. \ $ 불일치가 발생한 문자가 패턴에 없는 문자라면? >
- 문자 M은 패턴(BANANA)에 없는 문자이므로 패턴의 위치를 인덱스 1 ~ 5로 한 자리씩 옮기면서 비교하더라도 절대 일치할 수가 없다.
- 따라서, 패턴의 위치를 패턴의 길이(6)만큼 바로 넘겨 검사를 진행하면 된다.
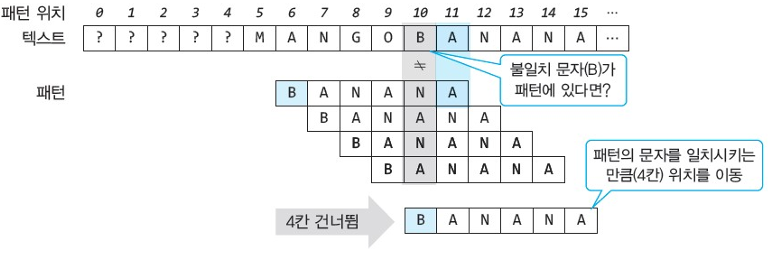
< $Case \ 2. \ $ 불일치가 발생한 문자가 패턴에 있는 문자라면? >
- 패턴의 맨 뒤 글자인 A는 일치하고, 다음 글자인 N은 텍스트 B와 일치하지 않는다.
- 이러한 경우는 텍스트의 B는 패턴에 존재하는 문자이므로 패턴의 B 위치가 텍스트의 B 위치와 일치하도록 건너뛰면 된다.
4. 시프트 테이블 생성
$e.g.$
- 패턴:
BANANA - 패턴 길이:
m = 6 - 문자 집합:
ASCII (0 ~ 127) - 기본 규칙:
- 불일치 발생 시 패턴에 없는 문자 →
이동 거리 = m - 불일치 발생 시 패턴에 있는 문자 →
마지막 문자 기준 거리
- 불일치 발생 시 패턴에 없는 문자 →
< 1. 패턴 인덱스 확인 >
- 마지막 인덱스 =
5 - 마지막 문자 =
A
| 인덱스 | 0 | 1 | 2 | 3 | 4 | 5 |
| 문자 | B | A | N | A | N | A |
< 2. 이동 거리 계산 >
$이동 거리 = (m-1)-i$
| 문자 | 인덱스($i$) | 계산식 | 이동거리 |
|---|---|---|---|
| B | 0 | 5 - 0 | 5 |
| A | 1 | 5 - 1 | 4 (X) |
| N | 2 | 5 - 2 | 3 |
| A | 3 | 5 - 3 | 2 (X) |
| N | 4 | 5 - 4 | 1 |
| A | 5 | 마지막 문자는 제외 | X |
< 3. 시프트 테이블 작성 >
| 문자 | 이동거리 | 설명 |
|---|---|---|
| A | 2 | 마지막 A 기준 (인덱스 3) |
| N | 1 | 마지막 N 기준 (인덱스 1) |
| B | 5 | 마지막 B 기준 (인덱스 0) |
| 나머지 | 6 | 패턴에 없음 |
위 과정을 통해 아래의 그림과 같은 시프트 테이블(shift table)이 만들어진다.

5. 소스코드
1
2
3
4
5
6
7
8
9
10
11
# 시프트 테이블 만들기
NO_OF_CHARS = 128 # 아스키 문자 개수
def shift_table(pat):
m = len(pat) # 패턴의 길이
tbl = [m] * NO_OF_CHARS # 시프트 테이블 초기화(기본 이동 거리 = m)
for i in range(m-1): # 패턴의 마지막 문자를 제외한 모든 문자에 대해
tbl[ord(pat[i])] = m-i-1 # 불일치 발생 시 이동할 거리 계산
return tbl
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
# 호스풀 알고리즘
def search_horspool(T, P):
m = len(P) # 패턴 문자열 길이
n = len(T) # 텍스트 문자열 길이
t = shift_table(P) # 패턴 기반으로 시프트 테이블 생성
i = m-1 # 텍스트에서 패턴의 마지막 문자가 맞춰질 위치 인덱스
while(i <= n-1): # 텍스트 범위를 벗어나지 않는 동안 반복
k = 0
while k <= m-1 and P[m-1-k]==T[i-k]: # 패턴의 끝에서 왼쪽으로 이동하며 문자 비교
k += 1 # 문자가 일치하면 다음 문자로 이동
if k == m: # 패턴의 모든 문자가 일치할 경우
return i-m+1 # 패턴이 시작된 텍스트의 인덱스 반환
else:
tc = t[ord(T[i-k])] # 불일치가 발생한 텍스트 문자에 대한 시프트 값 조회
i += max(1, (tc-k)) # 시프트 거리 계산
return -1 # 패턴을 찾지 못한 경우
# 호스풀 알고리즘 테스트
print("패턴의 위치:", search_horspool("APPLEMANGOBANANAGRAPE", "BANANA"))
1
2
# 출력 결과
패턴의 위치: 10
6. 복잡도 분석
최악의 경우 (worst case): $O(mn)$
- 8행의 외부 루프는 $n-m$번 반복한다.
- 또한, 하나의 위치에서 패턴을 비교하는데 패턴의 길이($m$) 만큼의 비교가 필요하다.
평균의 경우 (average case): $O(n)$
- 무작위 텍스트에 대해서는 거의 $O(n)$의 성능을 나타낸다.
- 이는 억지 기법보다 훨씬 효울적이다.